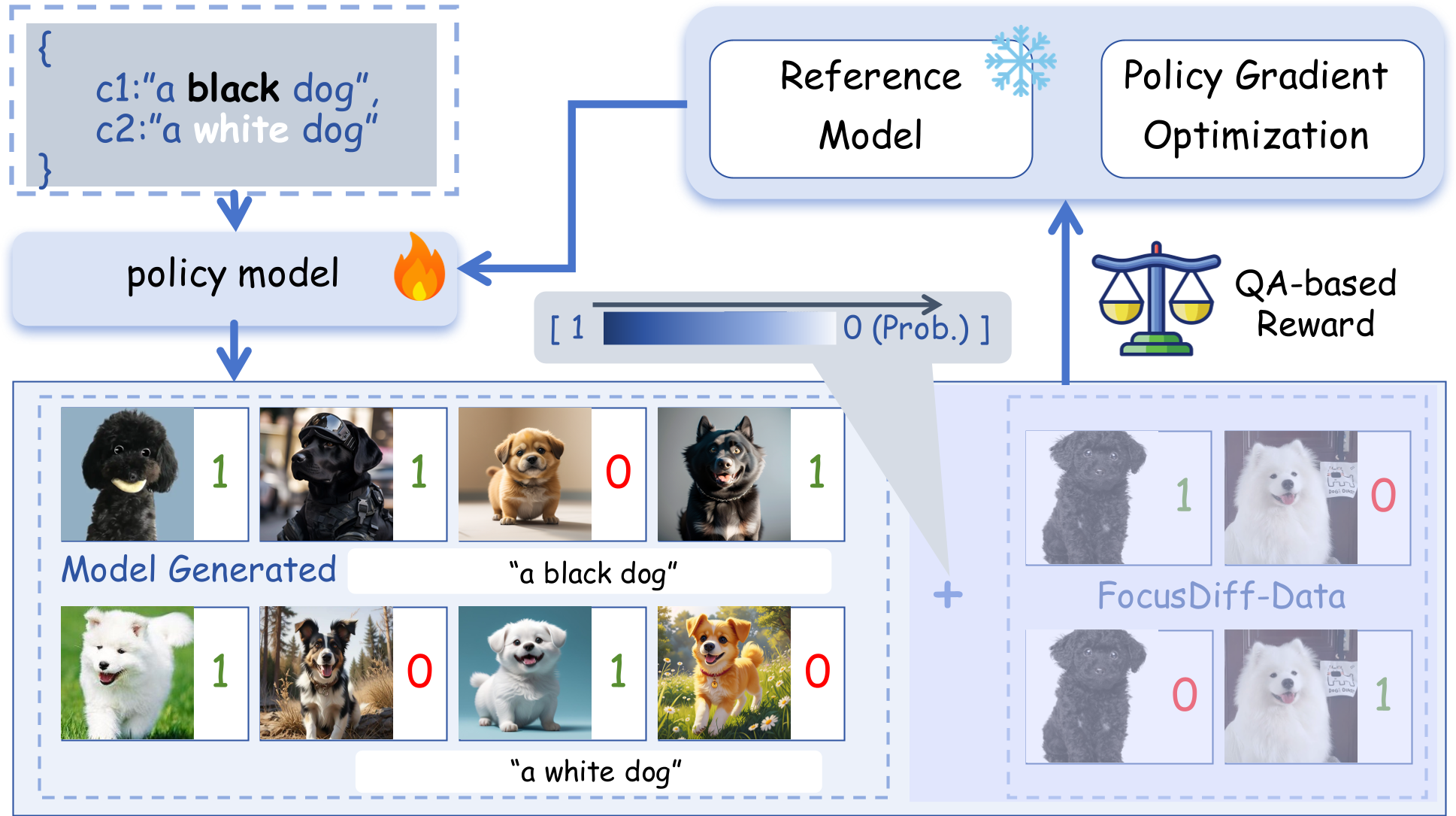
FocusDiff addresses the challenge of fine-grained semantic control in AR-based image generation. While AR models excel in capturing global semantics, they often struggle with subtle distinctions. And FocusDiff enhances text-to-image alignment through two main innovations:
FocusDiff addresses the challenge of fine-grained semantic control in AR-based image generation. While AR models excel in capturing global semantics, they often struggle with subtle distinctions. And FocusDiff enhances text-to-image alignment through two main innovations:
1. FocusDiff-Data: A curated dataset of paired prompts and images with subtle semantic variations.
2. Pair-GRPO: A novel RL algorithm extending Group Relative Policy Optimization to emphasize fine-grained semantic differences during training.
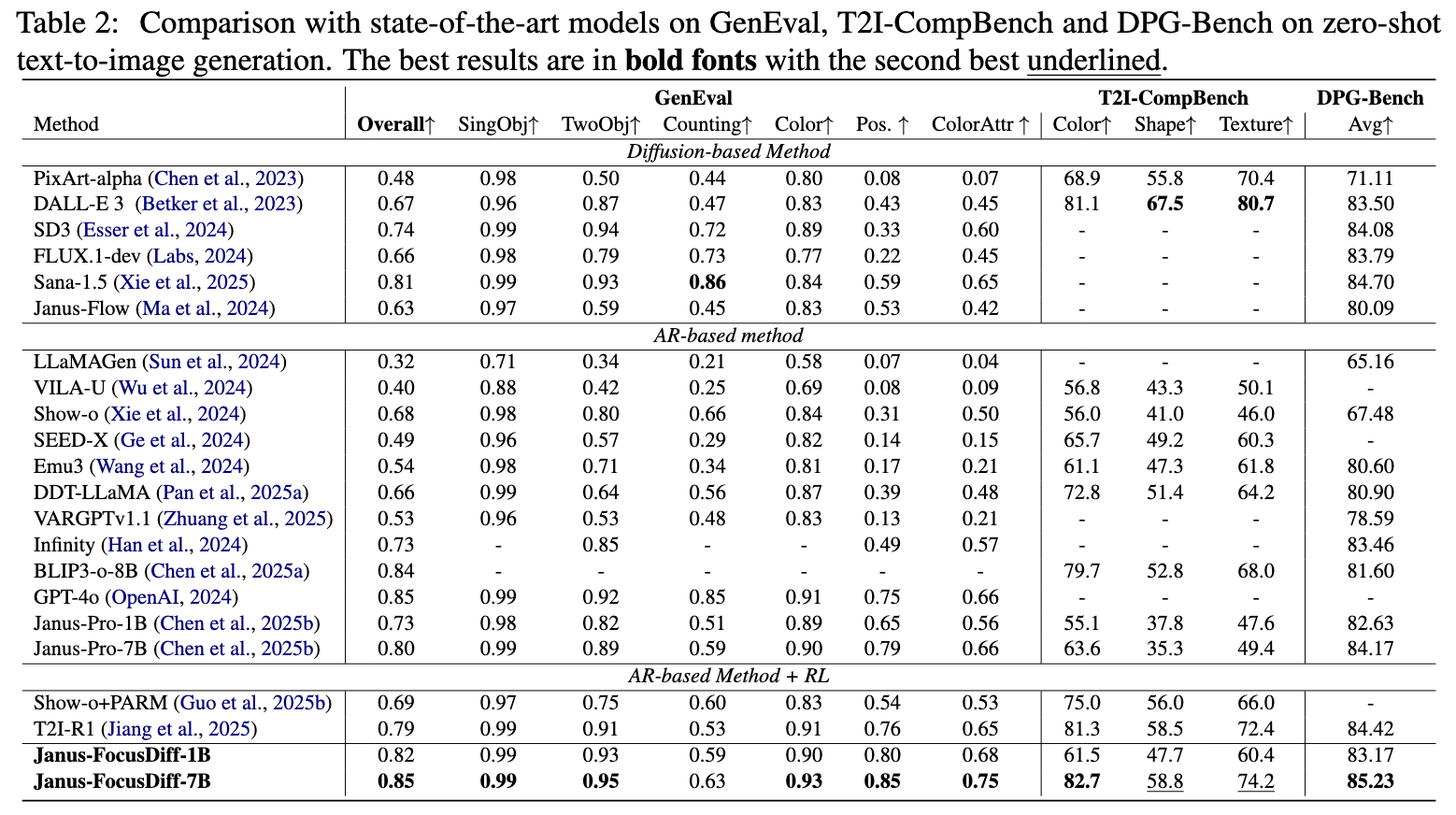
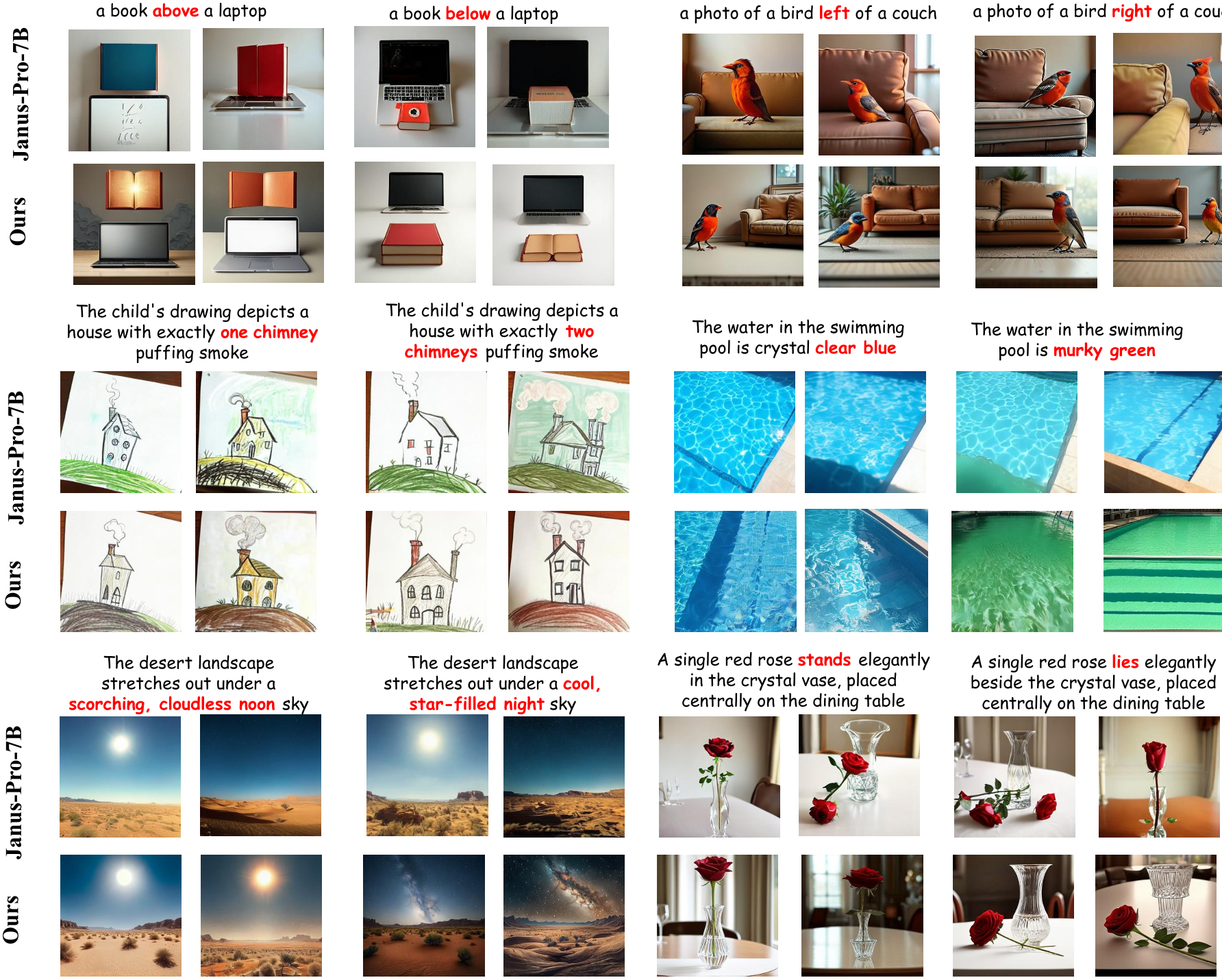
On this basis, we propose a new benchmark, i.e., PairComp. Each test case in Paircomp contains two similar prompts with subtle differences. By comparing the accuracy of the images generated by the model for each prompt, we evaluate whether the model has focused on the fine-grained semantic differences in the prompts to produce the corresponding correct images. The two prompts in a test case exhibit word-level differences that lead to noticeable distinctions in certain fine-grained semantic aspects. As shown in following figure, these differences can be categorized into six types: (1) Overall appearance difference; (2) Color difference; (3) Counting difference; (4) Position difference; (5) Style & Tone difference; (6) Text difference.